Seit ein paar Tagen bin ich stolzer Besitzer eines Opel Corsa-e. Vollelektrisch und hoffentlich gut zu laden mit der demnächst noch zu installierenden PV-Anlage.
Was ich gerade, ganz unabhängig davon, ausprobiert habe, ist, was das Autoradio mir von einem USB-Stick abspielt. Auf den USB-Stick habe ich eine MP3-Datei, eine OGG-Vorbis-Datei und eine Opus-Datei gepackt.
Für mich tatsächlich vollkommen verblüffenderweise (und auch wirklich erfreulicherweise) hat das Autoradio tatsächlich nicht nur den Steinzeit-kleinsten-gemeinsamen-Nenner MP3, sondern auch die Vorbis-Datei abgespielt! Opus hätte mich jetzt doch schon fast gewundert – aber Vorbis?! Das gab’s ja noch nie. Gut, die Vorbis-Entwickler sagen mittlerweile selbst, man möge doch bitte Opus benutzen, weil das Format in allen Belangen Vorbis überlegen ist. Aber Vorbis ist in allen Belangen MP3 überlegen. Und das nicht erst seit gestern.
Es wird doch nicht ein Hauch von Vernunft in die freie Wildbahn Einzug halten?! Nach all den Jahren unterstützt man ein (kosten-)freies Format, das schon immer besser war?
Irgendwann im Studium (das war von 2003 bis 2008! Also schon fast gar nicht mehr wahr!) habe ich mal eine Demo-CD gemacht. Für alle, die es interessiert hat. Um aufzuzeigen, dass Vorbis erheblich besser ist, als MP3 (Opus gab es damals noch gar nicht): Vergleich bei den selben Bitraten, wobei MP3 leicht hörbar erheblich schlechter war als Vorbis, mit auch für das ungeschulte Ohr hörbaren Artefakten. Und Vorbis mit einem im direkten Vergleich fast transparenten Ergebnis (je nach Bitrate).
Warum die Hersteller nicht schon damals Vorbis in ihren Kram integriert haben, habe ich bis heute nicht verstanden. Aber scheinbar ist jetzt — zumindest bei Opel – der Groschen gefallen!
Update 02.10.2023: Mittlerweile habe ich eine funktionierende Software-Lösung für PV-Überschussladen mit dem go-e-Charger, siehe go-e-pvsd läuft bzw. gleich die GitLab-Projektseite von go-e-pvsd :-)
Demnächst werde ich E-Auto-Fahrer. Nach über 11 Jahren bekommt mein VW Up als Nachfolger einen Opel Corsa E. Außerdem gibt’s demnächst auch noch eine PV-Anlage aufs Dach. Zeit also, sich mit dem möglichst effektiven Nutzen des selbstgemachten Stroms auseinanderzusetzen. Denn die Anlage muss ganz schön lang laufen, und ganz schön viel Strom erzeugen, um sich zu armortisieren.
In Vorbereitung der hoffentlich baldigen Lieferung des E-Autos habe ich schonmal eine Ladestation installiert. Meine Wahl fiel auf den go-eCharger HOMEfix, der schon verschiedentlich Testsieger war, und nettwerweise auch vergleichsweise günstig zu haben ist. Außerdem wirbt die Firma mit „Photovoltaikanbindung über [die] offene API-Schnittstelle (Programmierung erforderlich)“.
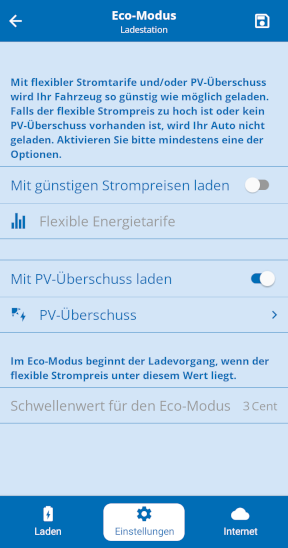
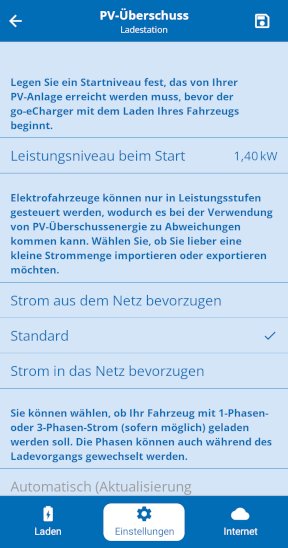
„Programmierung erforderlich“ – alles klar. Das werde ich wohl hinbekommen. Also: Was braucht es denn?! Die Handy-App zum Einstellen der Ladestation hat zum einen einen „Mit PV-Überschuss laden“-Schalter für den „Eco-Modus“, als auch einige Einstellungen dafür, wie denn mit PV-Überschuss genau umgegangen werden soll:
Also kann es ja eigentlich nur noch darum gehen, der Wallbox mitzuteilen, was der Wechselrichter gerade macht, bzw. welche Leistung gerade von den Solarzellen kommt, was verbraucht wird und was gerade übrig ist (also ins Netz eingespeist wird). Oder?!
Wie geht denn nun PV-Überschussladen mit dem go-e-Charger?
Es gibt eine offen dokumentierte API, die man u. a. via HTTP ansprechen kann. Klingt doch gut! Dann muss man doch sicher nur die aktuellen Daten vom Wechselrichter bzw. Smart Meter holen, passend verpacken, und der Wallbox mitteilen. Das sollte ja nun kein Problem sein.
Die Dokumentation der API-Schlüssel (Stand heute) ist ein bisschen spärlich, aber es gibt welche, die so aussehen, als wären sie die richtigen bzw. hätten zumindest mit dem PV-Überschussladen zu tun:
lpsc
R
milliseconds
Status
last pv surplus calculation
inva
R
milliseconds
Status
age of inverter data
pgrid
R
optional<float>
Status
pGrid in W
ppv
R
optional<float>
Status
pPv in W
pakku
R
optional<float>
Status
pAkku in W
… aber die sind doch alle „R“! Sollten da nicht ein paar „R/W“ sein?! Wie soll ich denn bitte dem Ding sagen, was gerade übrig ist?! Fragen wir doch mal den Support. Die werden mir ja sagen können, wie man die PV-Überschuss-Anbindung implementieren muss.
Und tatsächlich kam auch eine Antwort:
Hallo Herr Leupold,
vielen Dank für Ihre Anfrage!
Im Grunde müssen dem go-eCharger in der Tat die Daten des Wechselrichters (oder einer anderen Messeinrichtung) verständlich weitergegeben werden.
In der Regel wird das ganz einfach und simpel mit den Parameter amp (Ladestrom in 1A-Schritten) und frc (Ladefreigabe Ja/Nein).
Die PV-Parameter gelten als Vorbereitung auf den bald kommenden go-eController und sind noch nicht vollständig implementiert.
Der go-eController wird unsere allgemeine Lösung zum Überschussladen sein: https://go-e.com/de-de/produkte/go-e-controller
Für weitere Frage und Anliegen stehe ich Ihnen gerne zur Verfügung.
Mit freundlichen Grüßen
PV-Überschussladen mit dem go-e-Charger: Stand jetzt wohl eher Vaporware
Also kurz gesagt: Ich kann dem go-e-Charger via API sagen, mit wieviel Ampere er ausspucken soll, und ob oder ob nicht er laden soll. Und das war’s. Heißt: Die komplette Logik und Regelung muss extern implementiert werden, und das Ding macht selber überhaupt nichts im Puncto PV-Überschussladen.
Heißt: Will man das machen, was hier mit der Voraussetzung „Programmierung erforderlich“ beworben wird, dann ist die Ladestation nichts anderes als eine schaltbare Steckdose. Die Arbeit muss ich selbst machen. Und die Einstellmöglichkeiten in der App sind vollkommen funktionslos. Weil es keine Möglichkeit gibt, der Ladestation irgendwelche Parameter einer PV-Anlage zu übermitteln.
Das finde ich dann doch etwas befremdlich. Wieso enthält eine Steuer-App Optionen ohne Funktion?! Und warum veröffentlicht man API-Schlüssel, die man überhaupt nicht nutzen kann?!
Um das zu erreichen, was hier meiner Wahrnehmung nach beworben und auch in der App-Oberfläche angeboten wird, wird auf ein noch nicht verfügbares zusätzliches Produkt verwiesen und auf zukünftige Entwicklung der API. Ich muss sagen, dass ich mir das anders vorgestellt hatte.
Es geht wohl schon … aber
Um tatsächlich mit dem go-e-Charger PV-Überschussladen zu realisieren, bleibt einem Stand jetzt wohl nichts anderes übrig, als die komplette Steuerung und Logik selbst zu implementieren, oder auf bestehende Lösungen wie OpenWB oder evcc zurückzugreifen. Ausprobiert habe ich bisher noch gar nichts, es gibt ja bisher weder ein E-Auto, noch eine PV-Anlage.
Und die von evcc fordern für die Anbindung eines go-e-Chargers ein kostenpflichtiges GitHub-Sponsoring von mindestens 2 $ pro Monat (sofern ich das richtig verstanden habe). Bei aller Liebe: Dafür bin ich Open-Source-Entwickler zu viel. entweder mache ich Open Source, oder ich lasse es. Es ist vollkommen legitim, mit Open Source auch Geld zu verdienen. Aber da kann ich ja dann auch gleich ein kommerzielles Closed-Source-Produkt anbieten, wenn ich die Nutzung von einer fortlaufenden Zahlung abhängig mache. Und nein, ich mache mir nicht die Mühe, den entsprechenden Check aus dem Quellcode zu werfen, und den Kram dann ohne Zwangszahlung zu bauen.
Bleibt abzuwarten, was diesbezüglich seitens go-e noch kommt. Aber den momentanen Zustand finde ich ernüchternd.
I put all static content which rarely changes inside /static/, e.g. CSS and JavaScript files. A client requests such a file only once and caches it, until it expires. Next time, it's not fetched from the server, but simply loaded from the cache. This lowers traffic and CPU cycles, saving bandwidth and power consumption for both server and client.
Principally, this is a good idea and something everybody running a HTTP server should do, in some way.
The problem
The problem is that if something is changed, a client already having cached the file in question won't notice the change: As said, it won't request the file from the server but load it from it's cache. This could lead to a messed up layout or even an unfunctional page if relevant portions of e.g. the CSS style have been changed, in the worst case for a full month.
According to what I found, there's no way to directly work around it. If a browser did cache such a file with a defined time to live, it won't request it again during that time. There's no server-side way to tell a client it should reload such a file. No way to invalidate the cache or the expire date, no way to bypass this mechanism.
The client can possibly force-reload the page (e.g. by pressing CTRL+F5 or such, depending on the browser used), including all already cached files. But some people may not know this, and in some situations this might even not be possible at all: E.g. I'm using the Kiwi Browser on my phone, which does not seem to even have such a force-reload function.
The solution
If a file's name changes, it doesn't matter if the content is the same or almost the same. For the client, it's another file. So I simply introduced a revision number. E.g. instead of /static/css/style.css, it's now /static/css/style-1.css, after the next change, it would be /static/css/style-2.css and so on. Each client will request a file renamed like this after the change (of course again cache it) and display the changes correctly.
But all the HTML has to be changed then! Here, Jekyll, the lovely static web page generator, comes into play.
I simply created a YAML data file, which acts as a map for all the static content I want to handle like this. E.g. one could call it _data/static.yml, with entries like this:
This works as well for CSS or JavaScript files, as soon as a "front matter" is added. E.g. one would reference such a file inside a CSS file like that:
The parsed result delivered to _site/ is simply the CSS file like before (as we did not apply any layout), but with the stuff referenced by {{ ... }} replaced with the real thing.
This way, if some "static" file changes, one only has to bump the revision counter and update the _data/static.yml file. Which are two additional steps, but this does not happen too often. And the rest happens automagically :-) Still, the static stuff is cached as it should be, but when changes are done, everybody gets the new version.
Diesen Sommer haben wir die noch (gar nicht so) alte Brennkammer unseres Kachelofens durch eine wasserführende ausgetauscht, die nicht nur den Kachelofen, sondern auch unseren Pufferspeicher aufheizt (namentlich eine Leda Diamant H100 W). Netterweise wird, bedingt durch die günstige Konstruktion unserer Heizung, über den Pufferspeicher nicht nur unser Brauchwasser erhitzt; auch die Flächenheizung wird über den Speicher versorgt. Somit heizt jetzt die Brennkammer nicht mehr nur Wohn- und Esszimmer, sondern anteilig auch das ganze Haus.
Befeuert wird der Heizeinsatz ausschließlich mit Windbruch- und Käferholz aus dem schwiegerelterlichen Wald, der wenige Kilometer entfernt liegt. Von daher sehe ich das – Feinstaub hin oder her – als durchaus umweltfreundlich und vor allem (annähernd) CO2-neutral an.
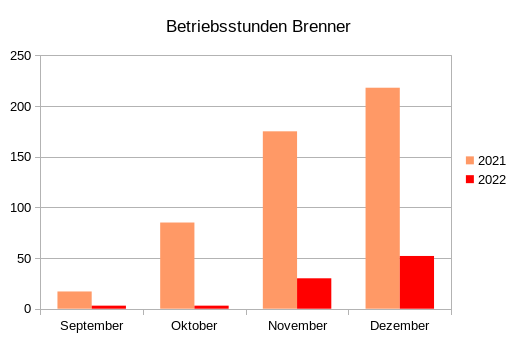
Besonders interessant ist allerdings das Einsparpotenzial beim Gasverbrauch. Wir haben (wie viele andere auch) eine Gastherme. Dank des vcontrold-Projekts1 zeichne ich, seitdem die Heizung installiert wurde, u. a. die Betriebsstunden des Brenners mit einem Raspberry Pi 1 auf2.
Der Dezember ist noch lang nicht vorbei, aber wenn man die Brennerstunden linear extrapoliert, kommt man auf folgendes Ergebnis:
Nun kann man nicht direkt die Brennerstunden mit der Gaseinsparung gleichsetzen (der Brenner läuft ja nicht immer auf 100 %), aber eine erhebliche Einsparung gab und gibt es definitiv: Im Schnitt haben wir (mit den Werten der Extrapolation für Dezember) die Stunden, in denen unsere Gastherme lief, um beachtliche 84 % reduziert. Gut, einschüren muss man schon. Mit nichts läuft die Anlage nicht, man braucht schon ein bisschen Brennholz (bisher ca. 4 Ster) Aber das war klar.
Am Ende des Winters poste ich hier jedenfalls nochmal die tatsächlichen Zahlen! Aber es sieht ganz danach aus, als ob sich diese doch nicht unerhebliche Investition gelohnt hat!
… dem ich vor einiger Zeit mal mit der Umstellung des veralteten Buildsystems auf CMake und dem Aufräumen des Quellcodes mit zu einem Neustart verholfen habe
… mit einem selbstgebauten Optolink-Adapter, der „richtige“ Schaltplan und die Fotos aus dem Wiki-Eintrag darüber sind von mir